He decidido dar por concluida la ordenación del Diccionario de la RAE, que me descargué con el programa buscaenrae.sh y el programa descargarae.sh hecho para la ocasión y que leía el archivo con la lista de palabras (al que impropiamente denominaba diccionario), para descargar, una a una, las páginas correspondientes.
Todo partió del trabajo que realicé para el proyecto del Diccionario Personal de Isidoro Valcárcel Medina, en 2015.
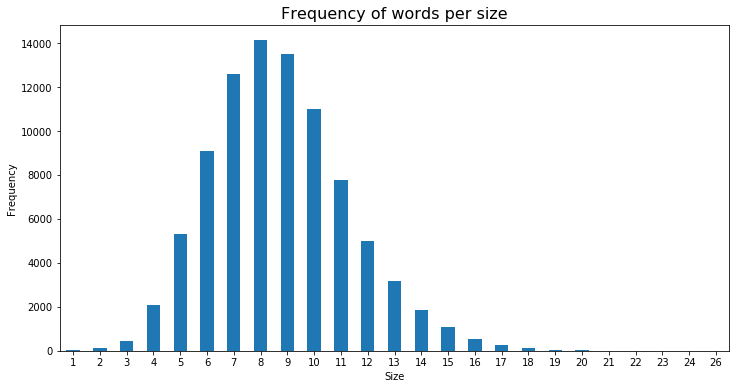
Ahí nos encontramos con la negativa de la RAE a ceder el diccionario en modo digital, así que tuve que teclear las entradas del mismo a lo largo de más de 3 meses. Finalmente, acabé teniendo una lista de 90940 palabras, algunas de las cuales eran acepciones repetidas. Si quitábamos las palabras que tenían más de una acepción y que estaban en el archivo etiquetadas con un número 1,2,… según procediera, nos quedaban 88296 palabras (debería llamarlas «entradas»).
Por supuesto, estaban plagadas de errores:
- En primer lugar los propios de tecleo.
- En segundo lugar (oh, my god!) tenía incluidas en mi colección las palabras que Isidoro había decidido incluir en su diccionario personal independientemente de las que hubiera en el de la RAE.
- En tercer lugar (y esto resultó ser lo peor), muchas palabras han «desaparecido», pues la entrada no corresponde a la palabra… por ejemplo, la palabra «poeta, tisa», no está en el diccionario sino en «poetisa», así que la palabra poeta no se encuentra en la RAE como tal.
Así que el programa contemplaba la necesidad de decirme si tal o cual palabra no estaba en el diccionario de la RAE (en la versión online)
Actualización 2020
La Real Academia Española (RAE) y la Asociación de Academias de la Lengua Española (ASALE) han emprendido ya las tareas de redacción de la nueva edición de su Diccionario de la lengua española (DLE), que tendrá las características fijadas en la planta aprobada por todas las Academias de ASALE. Con el objetivo de que el desarrollo de esa nueva edición, forzosamente lento, no retrase la inclusión de nuevas palabras y acepciones ni la modificación de las ya incorporadas que necesiten enmienda, se ha optado por publicar estas actualizaciones anualmente.
La que ahora se pone a disposición de todas las personas interesadas recoge las modificaciones aprobadas por todas las Academias en 2020 y tendrá la consideración de versión electrónica 23.4.
Ya de paso, como podía hacerlo, me informé de si la palabra que estaba consultando era o no conjugada, lo que significaba que era un verbo. Un bonito plus que no esperaba.
Con la lista de errores generada, fui revisándolas palabra a palabra, las 1245 entradas no encontradas, entre las que estaban, ni más ni menos: poeta.
Así que a lo largo de los últimos meses del 2020 fui dejándome los ojos para ir revisando esos errores y fabricando una lista de palabras que se corresponda lo más posible con la «oficial» de la RAE.
Ha quedado una lista de 88024 «entradas» que se corresponden con 90452 palabras (ya teniendo en cuenta que algunas entradas o vocablos tienen varias palabras (a veces me confundo y denomino a eso acepciones).
Una vez corregida y revisada, aunque asumo aún un error considerable que no puedo prever, tengo la posibilidad de descargar el diccionario completo palabra a palabra con el programa buscaenrae.sh
#!/bin/bash
### FUNCIONES ÚTILES PARA EL PROGRAMA
# uso() Instrucciones del programa y salida en caso de error.
uso () {
echo "Uso: $0 salida palabra"
echo -e "\tsalida es un valor númerico que identifica:"
echo -e "\t[0] para generar un archivo HTML con la respuesta"
echo -e "\t[1] para generar un archivo TXT con la respuesta"
echo -e "\t[2] para generar una línea TXT con la respuesta"
exit
}
f_verbos="00000_VERBOS.txt"
f_errores="00000_ERRORES.txt"
# CONTROL DE ENTRADA DE VARIABLES y ASIGNACIÓN
if [ $# -lt 2 ]
then
# Reportar uso inapropiado
uso
else
salida=$1
if [ $# -eq 2 ]; then
palabra="$2"
elif [ $# -eq 3 ]; then
palabra="$2 $3"
elif [ $# -eq 4 ]; then
palabra="$2 $3 $4"
elif [ $# -eq 5 ]; then
palabra="$2 $3 $4 $5"
fi
# echo "Palabra es #$palabra#"
fi
# CONSULTA DEL SERVIDOR de la RAE simulando ser uno de los diversos navegadores posibles
navegador=(
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:15.0) Gecko/20100101 Firefox/15.0.1"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:77.0) Gecko/20100101 Firefox/77.0"
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:77.0) Gecko/20190101 Firefox/77.0"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/7046A194A"
)
rnd=`echo $(($RANDOM%${#navegador[@]}))` # Elegimos un navegador al azar
# Hacemos la petición a la web de la RAE
curl -s --user-agent "${navegador[$rnd]}" https://dle.rae.es/"$palabra" > ./"$palabra.html"
# PROCESAMOS EL ARCHIVO OBTENIDO (Cortamos, retiramos lo innecesario, etc)
# Si se trata de un verbo, quitar las conjugaciones
id_conjugacion="<div id='conjugacion'>"
esunverbo=`grep -c "$id_conjugacion" ./"$palabra.html"`
if [ $esunverbo -gt 0 ]
then
echo "$palabra es un verbo" >> $f_verbos
# ELIMINAMOS la(s) CONJUGACIÓN(ES)
sed -i "/${id_conjugacion}/d" ./"$palabra.html"
fi
# Si tiene más de una acepción (Calcular cuántas después de saber si es un verbo)
id_acepcion="<article id="
id_acepcion_fin="<\/article>"
num_acepciones=`grep -c "$id_acepcion" ./"$palabra.html"`
# Si no tiene acepciones, la palabra no existe. No continuamos.
if [ $num_acepciones -eq 0 ]
then
echo "$palabra no se ha encontrado en la RAE" >> $f_errores
rm "./$palabra.html"
exit
fi
# PARTIR en $num_acepciones EL FICHERO $palabra.html"
# acepciones y acepciones_fin son 2 arrays de líneas PRECISO CONVERTIRLOS a cortes[]
acepciones=`grep -n "$id_acepcion" ./"$palabra.html"|awk -F":" '{print $1}'|sed ':a;N;$!ba;s/\n/ /g'`
c=0
for i in $acepciones
do
let cortes[$c]=$(($i))
let c=$(($c+1))
done
acepciones_fin=`grep -n "$id_acepcion_fin" ./"$palabra.html"|awk -F":" '{print $1}'|sed ':a;N;$!ba;s/\n/ /g'`
c=0
for i in $acepciones_fin
do
let cortes_fin[$c]=$(($i))
let c=$(($c+1))
done
# GENERA FICHEROS palabra.X.html por cada ACEPCIÓN
for (( i=0; i<$num_acepciones; i++ ))
do
# echo "El comienzo del corte está en ${cortes[$((i))]}"
# echo "El fin del corte está en ${cortes_fin[$((i))]}"
sed "${cortes[$((i))]},${cortes_fin[$((i))]} !d" "./$palabra.html" > "./$palabra.$i.html"
# Distintas salidas del programa, en función de la variable "salida"
if [ $salida -gt 0 ] # Salida a modo TXT
then
w3m "./$palabra.$i.html" > "./$palabra.$i.txt"
if [ $salida -gt 1 ] # En una sóla línea
then
sed ':a;N;$!ba;s/\n/ /g' "./$palabra.$i.txt"|sed 's/ / /g' > "./$palabra.$i.1linea"
fi
fi
done
# BORRAR indica si dejar o no los archivos que no se deseen como salida
BORRAR=1
if [[ $BORRAR -eq 1 ]] && [[ $salida -gt 0 ]]
then
rm "./$palabra."*html
if [ $salida -eq 2 ]
then
rm "./$palabra."*txt
fi
fi
# SALIDA FORZADA
exit
Este programa era invocado con el siguiente miniprogramita que, leyendo de la lista de palabras corregidas que, impropiamente, denominé diccionariosinrepes.txt, obtiene las diversas, impropiamente denominadas, acepciones y las separa en 90452 archivos de una única línea.
#!/bin/bash
### FUNCIONES ÚTILES PARA EL PROGRAMA
# uso() Instrucciones del programa y salida en caso de error.
uso () {
echo "Uso: $0 [diccionario]"
exit
}
# CONTROL DE ENTRADA DE VARIABLES y ASIGNACIÓN
if [ $# -gt 1 ]
then
# Reportar uso inapropiado
uso
elif [ $# -eq 1 ]
then
diccionario=$1
else
diccionario=diccionariosinrepes.txt
fi
while IFS= read -r line
do
buscaenrae.sh 2 $line
done < $diccionario
Descargadas y archivadas en una estructura de carpetas obvia:
dict -> LETRA
Se pueden reordenar o «recompilar» en una LETRA, con sus definiciones incluidas, sin incluir, etc…
Lo hago usando otro script simple:
#!/bin/bash
# El diccionario completo está por acepciones en las carpetas
# dict/LETRA
# Cada acepción (en realidad entrada en el diccionario) tiene
# un archivo denominado PALABRA.N.1linea conteniendo su definición.
# (donde N es el número de acepción contando desde cero)
letras="A B C D E F G H I J K L M N Ñ O P Q R S T U V W X Y Z"
for letra in $letras
do
ls dict/$letra > dictporletra/$letra.archivos.txt
awk -F"." '{print $1}' dictporletra/$letra.archivos.txt > dictporletra/$letra.acepciones.txt
ls dict/$letra/*.0.1linea |awk -F"/" '{print $3}'|awk -F"." '{print $1}' > dictporletra/$letra.sinrepes.txt
cat dict/$letra/* > dictporletra/$letra.definiciones.txt
done
cat dictporletra/*.archivos.txt > DICCIONARIO_TOTAL.archivos.txt
cat dictporletra/*.acepciones.txt > DICCIONARIO_TOTAL.acepciones.txt
cat dictporletra/*.sinrepes.txt > DICCIONARIO_TOTAL.sinrepes.txt
cat dictporletra/*.definiciones.txt > DICCIONARIO_TOTAL.definiciones.txt
Pero queda por resolver un problema que me tiene algo martirizado desde hace meses y es que la ordenación es muy compleja realizarla, pues muchas entradas en el diccionario son dobles, como «ad hoc», pero las definiciones descargadas incluyen líneas que son del tipo: «i Escrito con…» y desde el punto de vista del uso del comando sort, es más o menos lo mismo que decir que si quiero ordenar las primeras como «adhoc», la «iEscrito» se sale de su lugar.
He ordenado muchas manualmente sobre esta compilación, pero es un trabajo absolutamente aberrante y seguro que se puede hacer mejor, así que de momento he decidido dejar de trabajar en esto y dar por cerrado este proyecto que, en realidad, es la puerta de entrada a muchos otros.
Espero que el orden no sea algo tan terrible en esos otros proyectos venideros.
Dejo a disposición pública el Diccionario Completo que he generado de esta manera, con la estructura de carpetas generada, así como los programas utilizados para su procesamiento.
RAE-COMPLETO.tar